C
byDreamy postedAug 10, 2005
거품정렬 Bubble Sort
이 첨부 파일에 있는 건 일반적인 함수의 형태이다. (int형 뿐 아니라 모든 형태의 자료형을 비교할 수 있도록 만든 것이다)
자료 배열의 선두 번지인 base,
자료의 개수 nelem,
레코드의 크기 width,
키값의 비교를 하는 함수 포인터 fcmp 를 뜻한다.
fcmp 함수는
int intcmp(const void *a, const void *b) 등을 뜻한다.
■ 버블 정렬 개념
주어진 파일에서 두 개의 인접한 레코드의 키를 비교하여 키 값에 따라 레코드의 위치를 서로 교환한다.
n개의 입력 레코드로 구성된 파일에서 오름차순으로 정렬할 경우 첫 번째 레코드와 두 번째 레코드의 키를 비교하여 키 값이 작은 레코드를 앞에 위치시킨 후, 두 번째 레코드와 세 번째 레코드의 키를 비교하여 키 값이 작은 레코드의 위치를 결정하는 과정을 반복해서 마지막으로 n-1번째와 n번째 레코드를 비교하여 위치를 교환하면 1회의 반복이 완료
이때 n번째 위치하는 레코드는 키 값이 가장 큰 레코드가 됨
다시 n 번째 위치한 레코드를 제외한 나머지 n-1개의 레코드를 위와 동일한 수행방법으로 반복하면 2회의 작업이 끝나며, n-1번째 위치한 레코드는 두 번째로 큰 레코드가 됨
이와 같은 작업을 반복 수행하며 마지막 n-1회의 반복에서는 첫 번째와 두 번째 레코드의 키를 비교하여 작은 키 값을 가진 레코드를 첫 번째에 위치시킴으로써 모든 작업이 완료됨
매 단계가 수행될 때마다 정렬이 아직 완료되지 않은 데이터들 중 가장 큰 데이터가 배열의 마지막으로 떠오른다고 하여 버블정렬
■ 버블 정렬 방법
배열 A 에서 n개의 데이터를 오름차순으로 정렬하는 단계
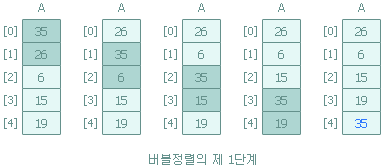
① 배열 안의 인접한 두 데이터 A[i]와 A[i+1]을 비교
② 왼쪽의 데이터인 A[i]가 더 크다면 두 데이터의 위치를 교환
③ 다음은 두 데이터 A[i+1]와 A[i+2]를 비교
위의 과정을 실행하면
① 제 1단계 : 배열 내에서 가장 큰 데이터가 배열의 마지막 자리에 위치
② 제 2단계 : 제 위치를 찾은 마지막 데이터를 제외한 나머지 데이터들로 수행
그 중 두 번째로 큰 데이터가 제 위치를 찾게됨
③ 이러한 방법으로 마지막 단계가 끝나면 정렬은 완료
■ n=5 일 때 입력 레코드 35, 26, 6, 15, 19 에 대한 버블 정렬 과정
초기 상태 35 26 6 15 19
1 단계 26 6 15 19 35
2 단계 6 15 19 26 35
3 단계 6 15 19 26 35
4 단계 6 15 19 26 35
정렬 완료 6 15 19 26 35
■ 버블 정렬 알고리즘
--------------------------------
void bubblesort(int A[], int n)
{ int i, j, temp;
for (i = n-1; i > 0 ; i--)
{
for (j = 1; j < = i ; j++)
{
if (A[j-1] > A[j])
{ temp = A[j-1];
A[j-1] = A[j];
A[j] = temp; }
}
}
}
--------------------------------
■ 성능
▷ 첫 번째 단계에서는 (n-1) 번의 비교가 수행
▷ 두 번째 단계에서는 (n-2) 번의 비교가 수행
▷ i 번째 단계에서는 (n-i) 번의 비교
▷ 평균 비교 횟수: O(n2)
▷ 가장 단순하여 정렬 알고리즘을 처음 시작하는 사람들이 이해하기 쉬운 알고리즘
▷ 간단하지만 수행속도가 느리므로 효율적인 프로그래밍을 위해서는 사용하지 않음
▷ 안정성은 유지되나 성능이 아주 미흡
▷ 최소값부터 찾아나가는 선택정렬과 반대로 최대값을 찾는 작업을 수행하며,
게다가 대충 정렬을 하는 것을 동시에 반복수행하므로 수행시간이 길어지는 단점
▷ 버블 정렬의 반복 과정 중에서 레코드의 교환이 발생하지 않으면 n개의 레코드는 이미 정렬된 상태이므로 정렬의 수행과정 중에서 정렬 상태를 점검하기 위해 플래그를 두어 레코드의 교환 여부를 점검하며, 이를 통해 정렬 수행시간을 단축할 수 있음
Articles
- API를 이용하는 유니코드와 ANSI 문자열간의 변환 방법
- CString을 유니코드로 변환 WCHAR에 저장하는 방법1
- 다이얼로그 기반 APP에서 Edit에 엔터키 먹게 하기
-
 아스키 코드표
아스키 코드표
- MFC에서 인자(argument)처리
- Base64 로 encoding / decoding 하는 예제
- 64bit DES 암복호화 코드1
- cmd.exe 명령 도움말
- 병합 정렬 Merge Sort
-
 힙 정렬 Heap Sort
힙 정렬 Heap Sort
-
 퀵 정렬 Quick Sort
퀵 정렬 Quick Sort
- 쉘 정렬 Shell Sort
-
 거품정렬 Bubble Sort
거품정렬 Bubble Sort
- 삽입정렬 Insertion Sort
-
 선택정렬 Selection Sort
선택정렬 Selection Sort
Designed by sketchbooks.co.kr / sketchbook5 board skin
Sketchbook5, 스케치북5
Sketchbook5, 스케치북5
Sketchbook5, 스케치북5
Sketchbook5, 스케치북5